OneData
OneData概述
OneData是阿里巴巴数据整合及管理体系,其方法论的核心在于:从业务架构设计到模型设计,从数据研发到数据服务,做到数据可管理 、可追溯、可规避重复建设。即数据只建设一次。
OneData体系架构
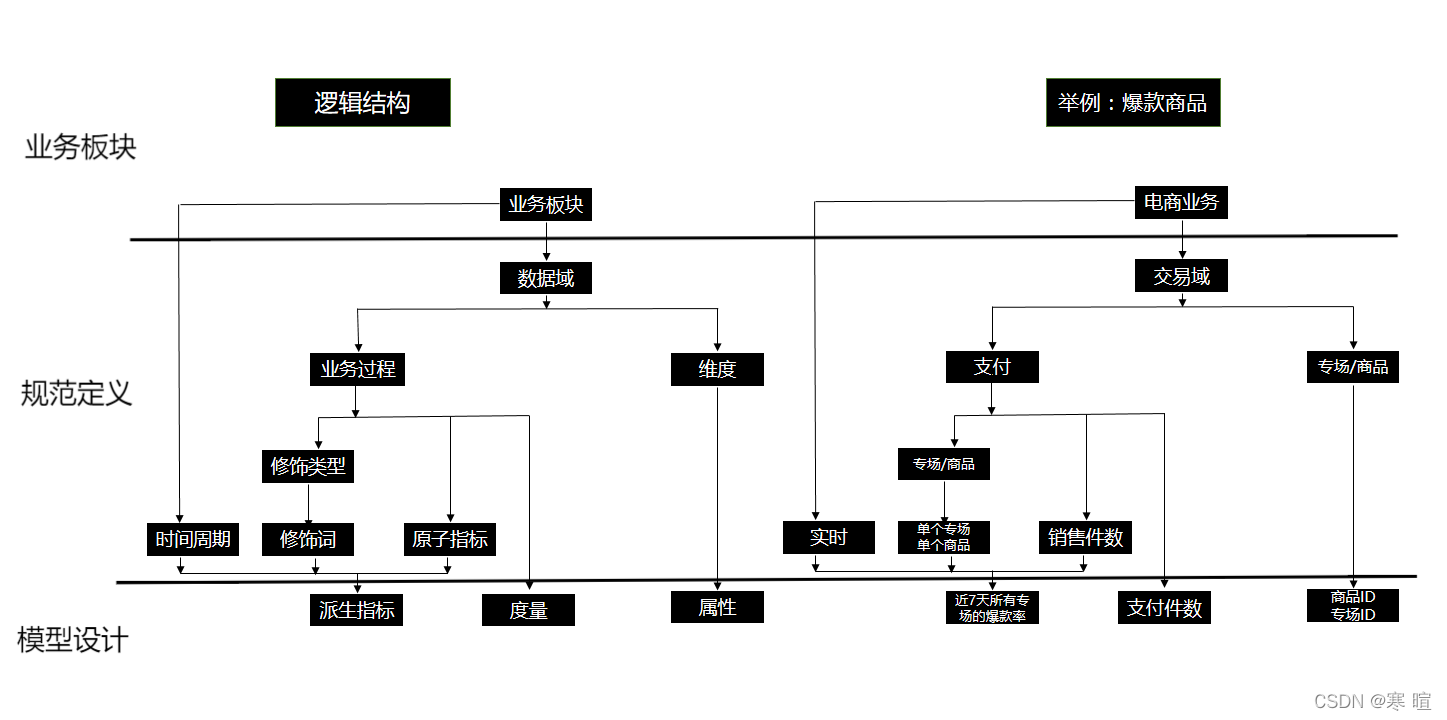
Onedata方法论分为三个阶段:业务板块、规范定义、模型设计。
业务板块:根据业务的属性划分出几个相对独立的业务板块,业务板块的指标或业务重叠性较小。
规范定义:结合业务板块相关数仓建设经验设计出的一套数据规范命名体系。
模型设计:以维度建模理论为基础,基于维度建模总线矩阵,构建一致性维度和事实。
规范定义
名词术语
数据域:指面向业务分析,将业务过程或者维度进行抽象的集合 其中 业务过程可以概括为一个个不可拆分的行为事件 在业务过程之下 可以定义指标;维度是指度的环境,如买家下单事件,买家是维度。为保障整个体系的生命力,数据域是需要抽象提炼,并且长期维护和更新的,但不轻易变动,在划分数据域时 既能涵盖当前所有的业务需求,又能在新业务进入时无影响地被包含进已有的数据域中和扩展新的数据域。 业务过程:如电商业务中的下单、支付、退款等都属于业务过程,业务过程是一个不可拆分的行为事实,就是企业活动中的事件。 时间周期:就是统计范围,如近30天、自然周、截止到当天等。 修饰类型:比较好理解的如电商中支付方式,终端类型等。 修饰词:除了维度意外的限定词,如电商支付中的微信支付、支付宝支付、网银支付等。终端类型为安卓、IOS等 原子指标:不可再拆分的指标如支付金额、支付件数等指标 维度:维度是度量的环境,用来反映业务的一类属性,这类属性的集合构成一个维度,也可以称为实体对象。如地理维度、时间维度。 维度属性:隶属于一个维度,比如时间维度中的年、季、月等内容。 派生指标:原子指标+修饰词+时间周期就组成了一个派生指标。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
指标体系
基础 原则
- 派生指标由原子指标、时间周期修饰词、若干其他修饰词组合得到。派生指标 = 原子指标+时间周期修饰词+修饰类型+修饰词。
- 原子指标、修饰类型和修饰词直接归属在业务过程下。
- 派生指标可以有多个修饰词,具体由派生指标语义决定。
- 派生指标归属唯一的原子指标。
- 原子指标由确定的英文字段名、数据类型和说明;派生指标继承原子指标的一切。
命名约定
-
指标命名尽量使用英文简写,其次是英文全拼,当指标英文名过长时,可以考虑使用汉语拼音首字母。
-
存量型指标在指标名后+stock,比如付费会员数,其对应的业务过程为mbr_stock。
-
时间周期修饰词表如下
中文名 英文名 中文名 英文名 最近1天 1d 自然月 cm 最近3天 3d 自然季度 cq 最近7天 1w 截至当日 td 最近14天 2w 年初截至当日 sd 最近30天 1m 零点截至当前 tt 最近60天 2m 财年 fy 最近90天 3m 最近1小时 1h 最近180天 6m 准实时 ts 180天以前 bh 未来7天 f1w 自然周 cw 未来4周 f4w 操作细则
-
派生指标的种类
派生指标可以分为三类:事务型指标、存量型指标和复合型指标。
-
事务型指标
是指对业务活动进行衡量的指标。例如新发商品数、重发商品数、新增注册会员数。这类指标需维护原子指标及修饰词。
-
存量型指标
是指对实体对象某种状态的统计。例如商品总数、注册会员总数。这类指标需维护原子指标及修饰词,在此基础上创建派生指标。
-
复合型指标
是指事务型指标和存量型指标的基础上复合而成的。
比率型:转换率、满意度。例如浏览UV-下单购买UV转换率。
比例型:百分比、占比。例如最近1天无线支付金额占比。
变化量型:例如最近1天营收上1天变化量。
变化率型:例如最近7天营收上7天变化率。
统计型:均值,分位数。例如自然月日均UV。
排名型:指标名上声明统计方法、名词、范围、语义。例如机械行业成交量降序TOP5。
对象集合型:可以将一些对象以KV对的方式存储在字段中方便前端展示。
-
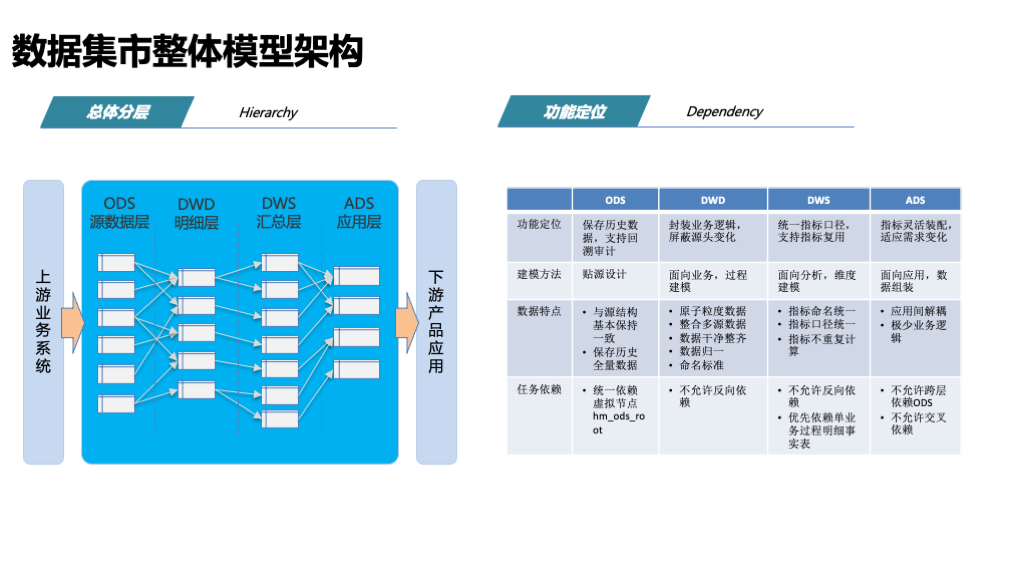
模型设计
OneData方法论将表数据模型分为三层,即操作数据层(ODS),公共维度模型层(CDM)和应用数据层(ADS)。其中CDM包含明细数据层(DWD)和汇总数据层(DWS)。
ODS
将业务系统数据无处理的存放在ODS层中。
DWD
采用维度模型方法作为理论基础,将维度退化至事实表中,减少事实表和维度表的关联。
DWS
加强指标的维度退化,采用更多的宽表化手段构建DWS层。一般对外数据服务由DWS层提供。
ADS
存放数据产品个性化的统计指标数据。一般ADS层不直接对外提供数据服务。
实施过程
指导方针
首先,在建设大数据数据仓库时,要进行充分的业务调研和需求分析,这是数据仓库建设的基石,业务调研和需求分析做得是否充分直接决定了数据仓库建设是否成功。
其次,进行数据总体架构设计,主要是根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵、抽象出业务过程和维度。
再次,对报表需求进行抽象整理出相关指标体系,使用 OneData 工具完成指标规范定义和模型设计。最后,就是代码研发和运维。
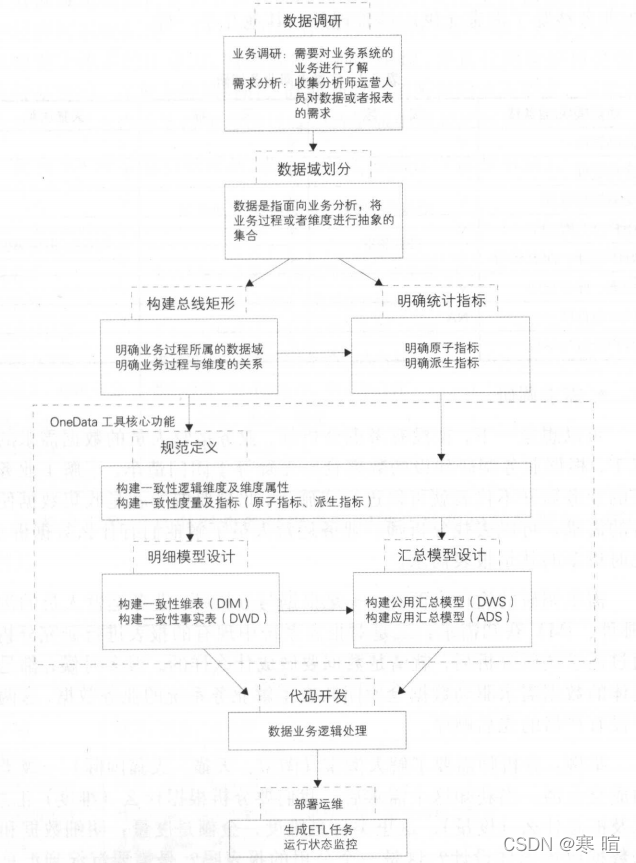
实施工作流
-
数据调研
-
业务调研
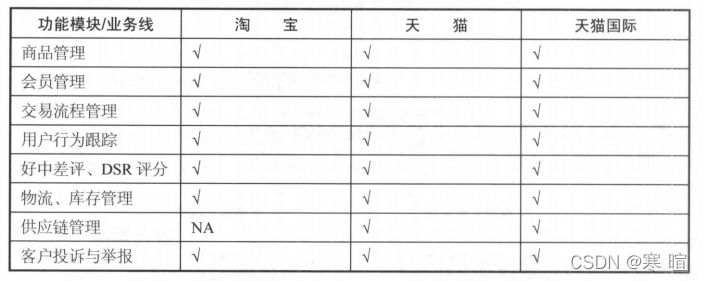
首先了解项目建设范围中的各个业务领域、业务线的业务有什么共同点和不同点,以及各个业务线可以细分为哪几个业务模块,每个业务模块的业务流程又是怎么样的。
比如下面三个电商业务线中,处理供应链管理模块不同外,其他几乎一样。
-
需求调研
需求调研的途径有两种:第一种是根据分析师、业务运营人员的沟通;二是对报表系统中现有报表进行研究分析。
比如我们要建设一个某行业的成交金额,首先要分析根据什么维度汇总,以及要汇总什么度量,明细层和汇总层怎么设计,是一个公用的数据吗?是需要沉淀到汇总表里面还是在外部报表工具中汇总。
-
-
架构设计
-
数据域划分
数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。业务过程可以概括为一个个不可拆分的行为事件。数据域是一个长期维护和更新,但是不轻易变动。
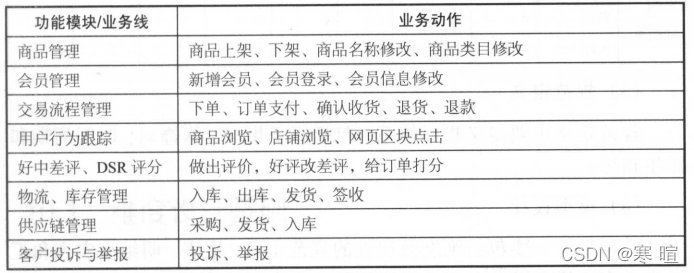
对业务过程进行归纳抽象后得到的数据域。
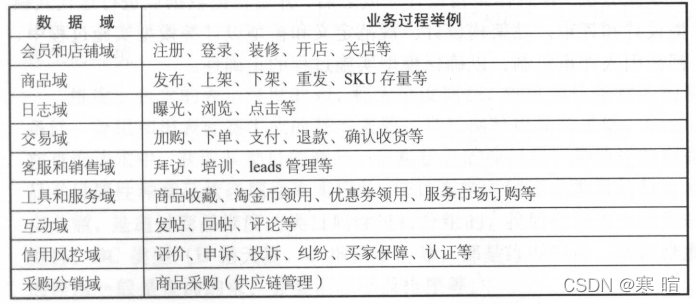
-
构建总线矩阵
总线矩阵需要明确每个数据域下有哪些业务过程;业务过程与那些维度相关。
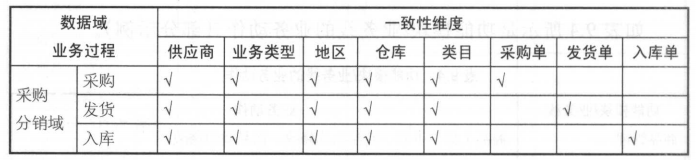
-
-
规范设计
规范定义主要定义指标体系,包含原子指标、修饰词、时间周期和派生指标。
-
模型设计
模型设计主要包括维度及属性的规范定义,相关表的模型设计。
-
总结
OneData的实施过程是一个高度迭代和动态的过程,一般采用螺旋式实施方法。
原文链接:https://blog.csdn.net/qq_41106844/article/details/122511769
如需转载请保留本文出处: https://zhe94.com/941.html