如果是 IT 老鸟,对于中间件、数据库中间件这些名词一定都不陌生,但是如果是程序员新人,如果你向他解释:“中间件就是和业务无关的技术组件”;有些新人可能依然会比较懵,啥是组件?什么叫和业务无关?
那么就让我先举个形象点儿的例子。
中间件是什么
干 IT 太累了,我准备辞职开了个烧烤摊,卖羊肉串;
卖羊肉串首先就得有羊肉,于是我就联系了很多养殖场,我又是一个比较负责人的人,为了保证羊肉的质量,我就去考察了一家又一家养殖场,同时我也是个“小气”的人,所以我考察过程中,和对方谈判、比价,最终选了一个养殖场作为我的羊肉供应商,为我提供羊肉。
经营了一阵子,这个养殖场提供的羊肉质量没有以前好了,那么我就重新考察、谈判、比价,如此反复,我投入了大量的时间和精力。
于是我找到了一个信得过的代理公司,约定要羊肉的质量和数量,谈好价钱,以后我只找代理商拿货,具体代理商找的哪家养殖场我不去过问,甚至代理商可以送货上门。
在这个例子里面,卖烧烤就是业务,我的烧烤摊是业务端,养殖场是底层,而这个信得过的代理公司,就是中间件。
数据库中间件:数据库就是底层,我们写的程序就是业务端,数据库中间件就是(和业务无关)的可以实现数据库一些功能的组件。
分库分表
当项目的数据量不断增大,单台数据库已经不足以支撑我们的业务量时,通常我们都会采用分库分表的策略。
如果分库分表自己在代码中实现的话,需要管理对个数据源,执行一次查询,需要定位到数据保存在哪个数据源上;当执行插入操作时,又需要确认需要将数据保存在哪个数据源中;
分库分表不仅有 SQL 解析和路由的问题,同时还会有 SQL 改写、并行执行、结果集合并等问题;所以项目经常会使用分库分表的组件,来屏蔽这些复杂的功能。
这类数据库中间件的实现方案基本上有两种:
1. Proxy 代理模式
在应用程序和数据库中间,单独部署一个代理层,所有的连接和数据库操作都发给这个代理层,由代理层去做底层的实现。
这样做对开发人员来说,是完全不需要知道下面做了什么的,甚至不需要做任何的代码改造,就可以完成接入;当然 Proxy 代理模式对代理层的高可用提出了很高的挑战,实现起来也很复杂。
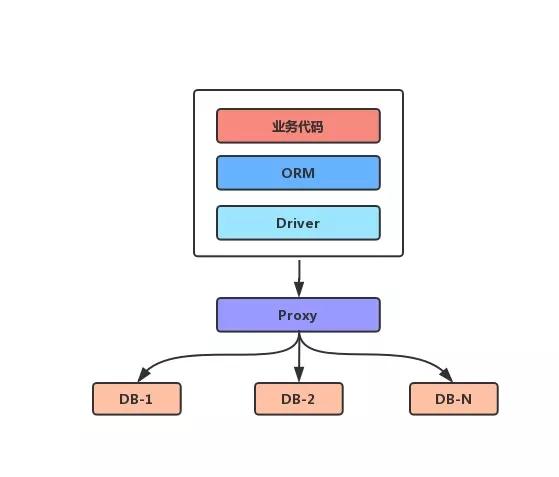
常见的框架有:MyCat(支持 MySQL, Oracle, DB2, PostgreSQL, SQL Server等主流数据库)、Cobar(阿里,已停止维护)、MySQL-Proxy、Atlas(360)、sharing-sphere(当当)等等。
2. Client 客户端模式
这种方式需要对现有程序进行改造,项目代码中需要加入分库分表功能的框架,同时也需要对代码中的配置或 SQL 做相应的修改。
Client 的模式,不需要有代理层,也就不需要考虑代理层高可用的问题(去中心化),实现起来也相对简单;当然缺点也很明显,代码的侵入性比较强,并且需要考虑版本升级的问题。
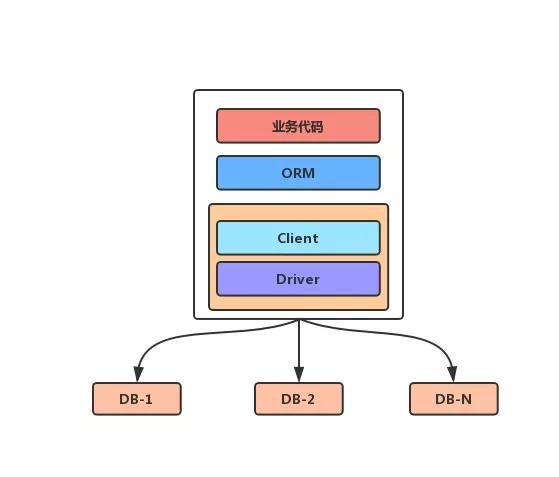
常见的框架有:TDDL(阿里,新名字DRDS)、zebra(美团)、sharding-jdbc(当当,这个做的也不错)等等。
数据增量订阅与消费
这个是基于对数据库增量日志解析,提供增量数据订阅和消费;最有名的是阿里的 Canal。
Canal 通过监听 Mysql 的 binlog 日志来获取数据,binlog 设置为 row 模式,能够获取到每一条新增、删除、修改的日志,同时还能获取到修改前后的数据。
通常我们可以利用这个中间件,实时感知到 Mysql 中的数据变化,将其数据更新到 NoSQL 数据中,比如 MongoDB、ES 等等;通常项目组加入这些非关系数据库,可以减轻数据库查询压力、在分库分表的架构中,还能起到全局查询的作用。
其它
除此之外,还有数据库同步中间件,比如阿里的Otter,基于数据库增量日志解析,准实时同步数据,支持两个库都可以写入,写入的数据同步到另外的库;数据库迁移中间件,实现不同数据库之间的数据迁移,比如阿里的yugong,实现了 Oracle 到 Mysql 的数据迁移。
总之,项目根据需要,可以引入解决问题的中间件或框架,但同时也要注意,引入这些中间件或框架可能会带来新的问题,一定要有相应的评估和解决方案。
如需转载请保留本文出处: https://zhe94.com/598.html



